Linux初始化通过bootmem/memblock引导内存分配进行内存管理,支持buddy system完成相关初始化后,将物理内存分配的功能转交给buddy system,buddy system是以page为单位分配方式。
对于内核要经常创建的对象, 如task_struct,fs_struct, mm_struct 通常会放到高速缓存中,保留基本结构,从而可以重复使用他们, 这里需要用到slab分配器。
slab分配器
- 通过
buddy system 申请空闲页 - 将申请到页处理为更小的分配单元,为其他子系统提供缓冲区存放内核对象
- 缓存经常使用的对象,释放后保存器初始状态,再次分配对象速度会很快
- 充分利用硬件高速缓存
历史发展#
- 1991 Initial K&R allocator
- 1996 SLAB allocator
- 2003 SLOB allocator
- 2004 NUMA SLAB
- 2007 SLUB allocator
- 2008 SLOB mulitlist
- 2011 SLUB fastpath rework
- 2013 Common slab code
- 2014 SLUBification of SLAB
…
常用的分配器#
- SLOB: K&R allocator (1991-1999)
- SLAB: Solaris type allocator (1999-2008)
- SLUB: Unqueued allocator (2008-today
SLOB#
- 简单的空闲对象列表管理
- 遍历列表查找合适的空间,没有的话申请向伙伴系统申请page增加堆栈大小.
- 碎片化严重
- 优化: 按照不同大小多个链表,减少碎片。
原理图#

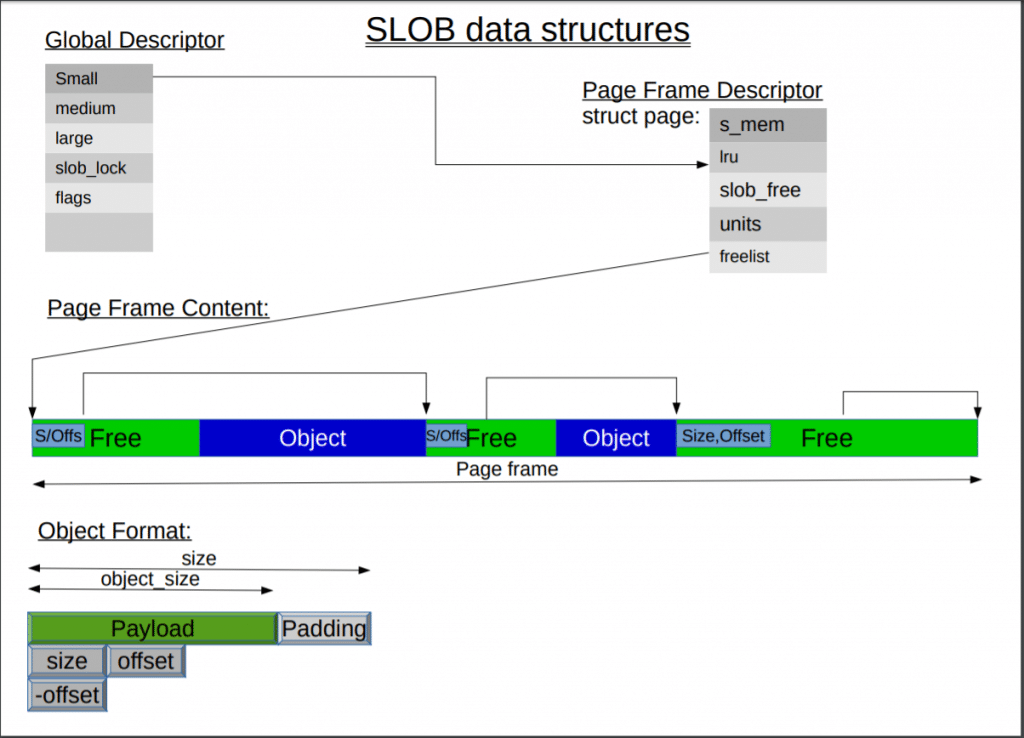
可以看到通过page中的freelist将一个pageframe中的空闲块一个一个链接起来.
具体实现#
涉及文件#
slob初期代码可以查看 slob: introduce the SLOB allocator
1
2
3
4
| /mm/slab.h
/include/linux/slab.h
/mm/slob.c
/mm/slab_common.c 与分配策略无关
|
数据结构#
标准的kmem_cache文件结构
1
2
3
| struct kmem_cache {
...
}
|
SLOB 原有结构在/mm/slob.c
1
2
3
4
5
6
7
8
9
10
| struct slob_block {
slobidx_t units;
};
typedef struct slob_block slob_t;
#define SLOB_BREAK1 256
#define SLOB_BREAK2 1024
static LIST_HEAD(free_slob_small);
static LIST_HEAD(free_slob_medium);
static LIST_HEAD(free_slob_large);
|
可以看在原有一条freelist的基础上增加为了三条freeslob*, 根据slab大小, 通过大小256,1024分为三段。
相关代码#
- 核心流程首先从
free_slob_small, free_slob_medium, free_slob_large,通过slob_page_alloc查找空闲块, 没有的话通过slob_new_pages申请新页
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| static void *slob_alloc(size_t size, gfp_t gfp, int align, int node,
int align_offset)
{
...
if (size < SLOB_BREAK1)
slob_list = &free_slob_small;
else if (size < SLOB_BREAK2)
slob_list = &free_slob_medium;
else
slob_list = &free_slob_large;
list_for_each_entry(sp, slob_list, slab_list) {
...
b = slob_page_alloc(sp, size, align, align_offset,\
&page_removed_from_list);
...
}
if (!b) {
b = slob_new_pages(gfp & ~__GFP_ZERO, 0, node);
...
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| #ifdef CONFIG_NUMA
void *__kmalloc_node(size_t size, gfp_t gfp, int node)
{
return __do_kmalloc_node(size, gfp, node, _RET_IP_);
}
EXPORT_SYMBOL(__kmalloc_node);
void *kmem_cache_alloc_node(struct kmem_cache *cachep, gfp_t gfp, int node)
{
return slob_alloc_node(cachep, gfp, node);
}
EXPORT_SYMBOL(kmem_cache_alloc_node);
#endif
|
- 根据
PAGE_SIZE判断使用 slob还是buddy system
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| static void *slob_alloc_node(struct kmem_cache *c, gfp_t flags, int node)
{
...
if (c->size < PAGE_SIZE) {
b = slob_alloc(c->size, flags, c->align, node, 0);
...
} else {
b = slob_new_pages(flags, get_order(c->size), node);
...
}
...
}
|
SLAB#
- 本地队列存储热点数据
- 每个cpu和每个节点分配队列。
- 远程节点的队列。
- 复杂的数据结构。
- 基于对象的内存策略。
- 指数增长节点*nr_cpus, 大量的内存被缓存。
- 每个处理器都必须每2HZ扫描其每个slab缓存的队列。
原理图#
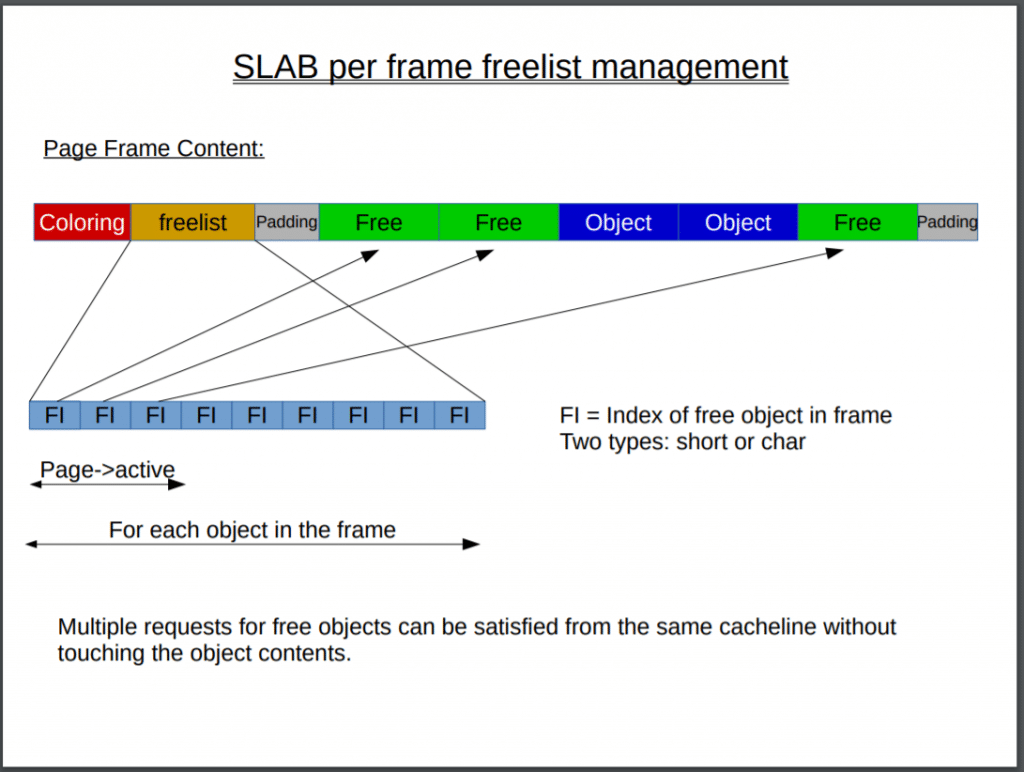
- 针对一个页面中的free
object的管理, 使用freelist做为索引数组 page->active保存了索引数组的最大长度。- 通过设置
Coloring更好支持硬件缓存, 将对象放置在slab中的不同起始偏移处,使得这些对象落在CPU高速缓存中不同的行,减少碰撞(collide)。
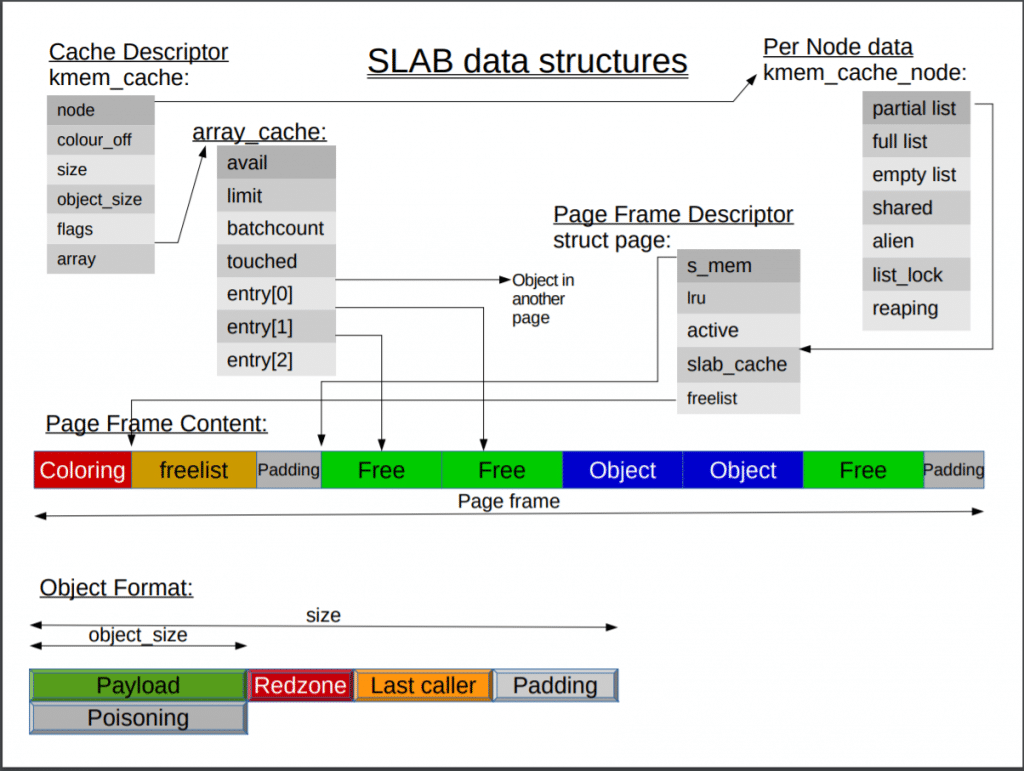
- 每个
cpu分配一个array_cache缓存结构,被称为cpu_cache, (cpu_cache 是per-CPU变量, 缓存可以不使用自旋锁,从而增加处理效率) - 针对
NUMA结构,缓存结构针对每个节点为了一个节点缓存kmem_cache_node, 通过三个queue(parital_list, full_list, empty_list)维护slab信息。 CPU Cache有每个CPU单独使用的L1 cache , L2 cache ,共享使用的 L3 cache, 结构中维护了本地节点per-CPU的array_cache, 节点共享的缓冲kmem_cache_node的shared,及远程节点缓冲的 alien。RedZone调试标识, 每一个对象末尾, 增加这个标识, 如果这个标识被修改, 判断是否发生缓冲区溢出last caller调试标识,位于RedZone之后, 2.6版本引入, 用于存放析构对象函数.Poinsing调试标识,通过创建和释放slab,将要感染的对象填充0x5A, 分配时检查, 如果被改变, 就知道之前是否使用过Payload就是缓存的object
在分析shared , alien 过程中发现一个特殊数字0xbaadf00d,
0xBAADF00D-bad food在微软的LocalAlloc-LMEM_FIXED函数中使用,用以在已启用调试堆的情况下,标识未初始化的分配堆内存。
来自 wiki - Hexspeak,看来贡献者应该有对windows开发比较了解。
具体实现#
涉及文件#
现有版本中涉及文件(v5.8-rc3)
1
2
3
4
| /mm/slab.h
/include/linux/slab_def.h
/mm/slab.c
/mm/slab_common.c 与分配策略无关
|
数据结构#
可以看到缓冲主要分为两部分, 一部分是per-CPU变量, 一部分保存的是节点缓存
1
2
3
4
5
| struct kmem_cache {
struct array_cache __percpu *cpu_cache;
...
struct kmem_cache_node *node[MAX_NUMNODES];
};
|
节点缓存区使用了slabs_partial, slabs_full, slabs_free管理slabs
1
2
3
4
5
6
7
8
| struct kmem_cache_node {
spinlock_t list_lock;
...
struct list_head slabs_partial;
struct list_head slabs_full;
struct list_head slabs_free;
...
};
|
下面这个是CPU缓存结构
1
2
3
4
5
6
7
| struct array_cache {
unsigned int avail;
unsigned int limit;
unsigned int batchcount;
unsigned int touched;
void *entry[];
};
|
可以看到默认情况下, 其他CPU的缓存,alien缓存, 特别的多出一个自旋锁lock
1
2
3
4
5
6
7
8
9
10
11
| struct alien_cache {
spinlock_t lock;
struct array_cache ac;
};
static int use_alien_caches __read_mostly = 1;
static int __init noaliencache_setup(char *s)
{
use_alien_caches = 0;
return 1;
}
|
相关代码#
下面是初始化时的代码片段在文件/mm/slab.c中, 可以看到对page->freelist和page->s_mem的设置,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| static void cache_init_objs(struct kmem_cache *cachep,
struct page *page)
{
...
if (!shuffled && OBJFREELIST_SLAB(cachep)) {
page->freelist = index_to_obj(cachep, page, cachep->num - 1) +
obj_offset(cachep);
}
...
for (i = 0; i < cachep->num; i++) {
objp = index_to_obj(cachep, page, i);
...
if (!shuffled)
set_free_obj(page, i, i);
}
...
}
|
1
2
3
4
5
| static inline void set_free_obj(struct page *page,
unsigned int idx, freelist_idx_t val)
{
((freelist_idx_t *)(page->freelist))[idx] = val;
}
|
1
2
3
4
5
| static inline void *index_to_obj(struct kmem_cache *cache,
struct page *page, unsigned int idx)
{
return page->s_mem + cache->size * idx;
}
|
通过page->active设置索引数组的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| static void *slab_get_obj(struct kmem_cache *cachep, struct page *page)
{
void *objp;
objp = index_to_obj(cachep, page, get_free_obj(page, page->active));
page->active++;
return objp;
}
static void slab_put_obj(struct kmem_cache *cachep,
struct page *page, void *objp)
{
unsigned int objnr = obj_to_index(cachep, page, objp);
...
page->active--;
if (!page->freelist)
page->freelist = objp + obj_offset(cachep);
set_free_obj(page, page->active, objnr);
}
|
可以看到分配顺序是先取cpu缓存, 通过cache_alloc_refill后还有一个回填到CPU缓存的动作。
1
2
3
4
5
6
7
8
9
10
| static inline void *____cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
...
ac = cpu_cache_get(cachep);
...
objp = cache_alloc_refill(cachep, flags);
ac = cpu_cache_get(cachep);
...
return objp;
}
|
CPU缓冲处理很简单高效
1
2
3
4
| static inline struct array_cache *cpu_cache_get(struct kmem_cache *cachep)
{
return this_cpu_ptr(cachep->cpu_cache);
}
|
如果不使用cpu缓存, 就判断节点share出来的缓存通过transfer_objects直接拷贝了, 否则话就会通过上面提到的slab_paritial或者slab_free将进行batchcount分配, 如果还是没有就直接调用cache_grow_begin 申请物理页面了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| static void *cache_alloc_refill(struct kmem_cache *cachep, gfp_t flags)
{
...
shared = READ_ONCE(n->shared);
if (!n->free_objects && (!shared || !shared->avail))
goto direct_grow;
shared = READ_ONCE(n->shared);
if (shared && transfer_objects(ac, shared, batchcount)) {
shared->touched = 1;
goto alloc_done;
}
while (batchcount > 0) {
page = get_first_slab(n, false);
if (!page)
goto must_grow;
...
batchcount = alloc_block(cachep, ac, page, batchcount);
fixup_slab_list(cachep, n, page, &list);
}
must_grow:
n->free_objects -= ac->avail;
alloc_done:
spin_unlock(&n->list_lock);
fixup_objfreelist_debug(cachep, &list);
direct_grow:
...
page = cache_grow_begin(cachep, gfp_exact_node(flags), node);
ac = cpu_cache_get(cachep);
if (!ac->avail && page)
alloc_block(cachep, ac, page, batchcount);
cache_grow_end(cachep, page);
...
}
...
return ac->entry[--ac->avail];
}
|
1
2
3
4
5
6
7
8
| static int transfer_objects(struct array_cache *to,
struct array_cache *from, unsigned int max)
{
...
memcpy(to->entry + to->avail, from->entry + from->avail -nr,
sizeof(void *) *nr);
...
}
|
针对跨节点情况, 如果是设置了SLAB_MEM_SPREAD, 分散到各个cpu缓存进行分配, 可以使用cpuset_slab_spread_node, mempolicy_slab_node两个方法得到节点编号, 通过 __cache_alloc_node进行分配。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| static void *alternate_node_alloc(struct kmem_cache *cachep,
gfp_t flags)
{
...
nid_alloc = nid_here = numa_mem_id();
if (cpuset_do_slab_mem_spread() && (cachep->flags & SLAB_MEM_SPREAD))
nid_alloc = cpuset_slab_spread_node();
else if (current->mempolicy)
nid_alloc = mempolicy_slab_node();
...
if (nid_alloc != nid_here)
return ____cache_alloc_node(cachep, flags, nid_alloc);
return NULL;
}
|
1
2
3
4
5
6
7
8
9
| #define REAPTIMEOUT_AC (2*HZ)
#define REAPTIMEOUT_NODE (4*HZ)
static void cache_reap(struct work_struct *w)
{
...
schedule_delayed_work_on(smp_processor_id(), work,
round_jiffies_relative(REAPTIMEOUT_AC));
}
|
我的机器 1s = 100HZ, 所以 1HZ 约等于 10ms, 也就是20ms进行以此缓冲扫描回收空闲对象
1
2
3
4
5
6
7
8
9
| [root@centosgpt ~]# cat /proc/interrupts | grep timer && \
sleep 1 && cat /proc/interrupts | grep timer
0: 4 0 IO-APIC 2-edge timer
LOC: 8475 8291 Local timer interrupts
HVS: 0 0 Hyper-V stimer0 interrupts
0: 4 0 IO-APIC 2-edge timer
LOC: 8577 8390 Local timer interrupts
HVS: 0 0 Hyper-V stimer0 interrupts
[root@centosgpt ~]#
|
释放alient远程缓冲时会先放到shared 缓冲中
1
2
3
4
5
6
7
8
9
| static void __drain_alien_cache(struct kmem_cache *cachep,
struct array_cache *ac, int node,
struct list_head *list)
{
...
if (n->shared)
transfer_objects(n->shared, ac, ac->limit);
...
}
|
SLUB#
Unqueued 无队列的设计 (针对SLAB)- 队列就是一个单页面中的
slab队列。 页面与CPU关联 - 使用
per-CPU partials链表 - 在一个
cpu完成实现快速通道 - 基于页面的策略。
- 多个级别的碎片整理功能。
- 当前的默认
slab分配器。
原理说明#
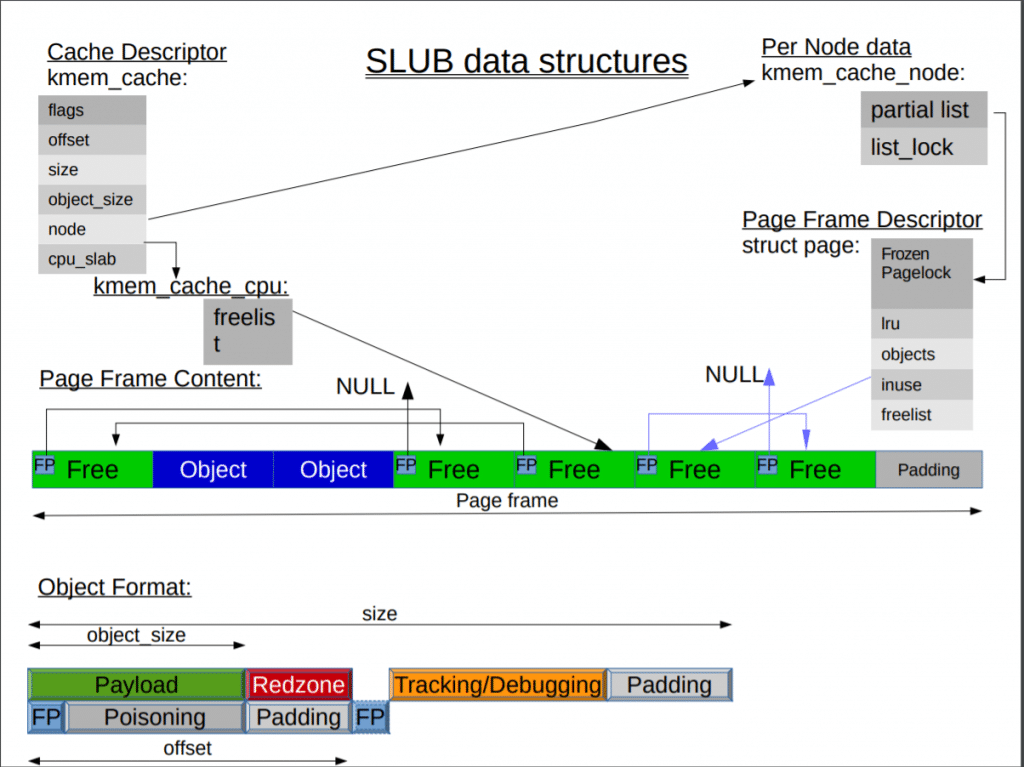
- 相比
slab, slub结构进行了精简, per-cpu缓存结构体简化 cpu node 结构简化, 使用partial_listFrozenPagelock:page->frozen 设置为1仅能存放在指定cpu的partial list中Payload就是缓存的objectRedZone调试标识, 增加这个标识, 如果这个标识被修改, 判断是否发生缓冲区溢出, 如果启用填写0xcc,不启用仅作填充(Padding)0xbbPoinsing调试标识,通过创建和释放slab,将要感染的对象填充0x5A, 分配时检查, 如果被改变, 就知道之前是否使用过Tracking/Debugging, 存放SLAB_STORE_USER相关数据存储最后的拥有者信息Free Pointer,一个大小为sizeof(void*)指针, 在设置Poison时,填充POISON_FREE(0x6b)Padding 填充数据 0x5a
具体实现#
涉及文件#
1
2
3
4
| /mm/slab.h
/include/linux/slub_def.h
/mm/slub.c
/mm/slab_common.c 与分配策略无关
|
数据结构#
可以看到和 slab使用同样结构kmem_cache, 缓冲主要分为两部分, 一部分是per-CPU变量, 一部分保存的是节点缓存,不过cpu_slab类型略有调整
1
2
3
4
5
| struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
...
struct kmem_cache_node *node[MAX_NUMNODES];
};
|
也就是这个结构直接挂在了页面page
1
2
3
4
5
6
7
8
9
10
| struct kmem_cache_cpu {
void **freelist;
unsigned long tid;
struct page *page;
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct page *partial;
/* Partially allocated frozen slabs */
#endif
...
};
|
节点保存一个partial指针做为Cpu缓存的备份
1
2
3
4
5
6
7
| struct kmem_cache_node {
spinlock_t list_lock;
...
unsigned long nr_partial;
struct list_head partial;
...
};
|
相关代码#
先去per-CPU的cpu_slab, 取不到通过 __slab_alloc再申请
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
{
...
do {
...
c = raw_cpu_ptr(s->cpu_slab);
} while (...);
...
if (...) {
object = __slab_alloc(s, gfpflags, node, addr, c);
stat(s, ALLOC_SLOWPATH);
} else {
...
}
...
}
|
配置了CONFIG_SLUB_CPU_PARTIAL, 从per-CPU的partial申请
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
...
if (slub_percpu_partial(c)) {
page = c->page = slub_percpu_partial(c);
slub_set_percpu_partial(c, page);
stat(s, CPU_PARTIAL_ALLOC);
...
}
...
freelist = new_slab_objects(s, gfpflags, node, &c);
...
}
|
否则需要考虑从备用节点parital申请或重新申请页
1
2
3
4
5
6
7
8
9
10
| static inline void *new_slab_objects(struct kmem_cache *s, gfp_t flags,
int node, struct kmem_cache_cpu **pc)
{
...
freelist = get_partial(s, flags, node, c);
...
page = new_slab(s, flags, node);
...
}
|
从当前节点寻找partial,找不到如果存在其他节点寻找其他节点上partial
1
2
3
4
5
6
7
8
9
| static void *get_partial(struct kmem_cache *s, gfp_t flags, int node,
struct kmem_cache_cpu *c)
{
...
object = get_partial_node(s, get_node(s, searchnode), c, flags);
...
return get_any_partial(s, flags, c);
}
|
备用节点没有可用直接申请物理页面
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| static struct page *new_slab(struct kmem_cache *s, gfp_t flags, int node)
{
...
return allocate_slab(s,
flags & (GFP_RECLAIM_MASK | GFP_CONSTRAINT_MASK), node);
}
static struct page *allocate_slab(struct kmem_cache *s,
gfp_t flags, int node)
{
...
page = alloc_slab_page(s, alloc_gfp, node, oo);
...
}
|
参考及引用#
Christoph Lameter Slab allocators in the Linux Kernel: SLAB, SLOB, SLUB
linux内存源码分析 - SLAB分配器概述
Linux slab allocator and cache performance
cache coloring on slab memory management in Linux kernel
(v5.8-rc3)