背景:#
故障源于知识星球的一个案例:
我们的数据库需要做在线升级丝滑的验证,所以构造了一个测试环境,客户端Sysbench 用长连接一直打压力,同时Server 端的数据库做在线升级,这个在线升级会让 Server进程重启,所以毫无疑问连接会断开重连,所以期望升级的时候 Sysbench端 QPS 跌0几秒钟然后快速恢复。
但是每次升级都是 Sysbench端 QPS永久跌0,再也不能恢复,所以需要分析为什么,问题出在哪里?有人说是服务端的问题因为只有服务端做了变更
整个测试过程中 Sysbench 是配置的2个连接去压 Server
故障重现:#
https://articles.zsxq.com/id_zj5qazqa4odz.html 下面也保留一份。
1
| docker run -it -d --net=host -e MYSQL_ROOT_PASSWORD=123 --name=plantegg mysql
|
1
2
3
| yum install -y java-1.8.0-openjdk.x86_64 java-1.8.0-openjdk-devel.x86_64 podman-docker.noarch wireshark sysbench mysql.x86_64
mysql -h127.1 -uroot -p123
|
1
| mysql -h127.1 -uroot -p123 -e "create database test"
|
1
| sysbench --mysql-user='root' --mysql-password='123' --mysql-db='test' --mysql-host='127.0.0.1' --mysql-port='3306' --tables='16' --table-size='10000' --range-size='5' --db-ps-mode='disable' --skip-trx='on' --mysql-ignore-errors='all' --time='1180' --report-interval='1' --histogram='on' --threads=1 oltp_read_only prepare
|
1
| sysbench --mysql-user='root' --mysql-password='123' --mysql-db='test' --mysql-host='127.0.0.1' --mysql-port='3306' --tables='16' --table-size='10000' --range-size='5' --db-ps-mode='disable' --skip-trx='on' --mysql-ignore-errors='all' --time='1180' --report-interval='1' --histogram='on' --threads=1 oltp_read_only run
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| # mysql -h127.1 -uroot -p123
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 14
Server version: 8.3.0 MySQL Community Server - GPL
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]> show processlist;
+----+-----------------+-----------------+------+---------+------+------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+-----------------+------+---------+------+------------------------+------------------+
| 5 | event_scheduler | localhost | NULL | Daemon | 94 | Waiting on empty queue | NULL |
| 13 | root | 127.0.0.1:33492 | test | Sleep | 0 | | NULL |
| 14 | root | 127.0.0.1:51398 | NULL | Query | 0 | init | show processlist |
+----+-----------------+-----------------+------+---------+------+------------------------+------------------+
MySQL [(none)]> kill 13;
Query OK, 0 rows affected (0.000 sec)
|
故障现象#
这个地方开始没有注意到, 由于已经给出分析结果的案例, 自己没有去主动分析。后面还是要先自己分析一下再看分析结果。
1
2
3
4
5
| [ 20s ] thds: 1 tps: 620.98 qps: 8699.68 (r/w/o: 8699.68/0.00/0.00) lat (ms,95%): 2.03 err/s: 0.00 reconn/s: 0.00
[ 21s ] thds: 1 tps: 657.00 qps: 9196.98 (r/w/o: 9196.98/0.00/0.00) lat (ms,95%): 1.86 err/s: 0.00 reconn/s: 0.00
[ 22s ] thds: 1 tps: 660.02 qps: 9238.30 (r/w/o: 9238.30/0.00/0.00) lat (ms,95%): 1.79 err/s: 0.00 reconn/s: 0.00
[ 23s ] thds: 1 tps: 509.99 qps: 7136.82 (r/w/o: 7136.82/0.00/0.00) lat (ms,95%): 1.67 err/s: 0.00 reconn/s: 0.00
[ 24s ] thds: 1 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00
|
- 2. 使用访问3306无法链接, 使用mysql访问返回99
plantegg 还验证了不同错误的返回信息,举一反三的能力
1
2
3
4
| # mysql -h127.1 -uroot -p123
ERROR 2002 (HY000): Can't connect to MySQL server on '127.1' (99)
# perror 99
OS error code 99: Cannot assign requested address
|
- 3. tcp链接不停增长, 大量CLOSE_WAIT状态
1
2
3
4
5
6
7
8
9
10
| # ss -s
Total: 21548
TCP: 26392 (estab 298, closed 5002, orphaned 12, timewait 5000)
Transport Total IP IPv6
RAW 0 0 0
UDP 8 5 3
TCP 21390 21226 164
INET 21398 21231 167
FRAG 0 0 0
|
1
2
3
4
5
| # netstat -an|grep 3306
tcp 132 0 127.0.0.1:60010 127.0.0.1:3306 CLOSE_WAIT
tcp 132 0 127.0.0.1:60002 127.0.0.1:3306 CLOSE_WAIT
tcp 0 0 127.0.0.1:34984 127.0.0.1:3306 ESTABLISHED
。。。
|
1
2
3
| # top
4156 root 20 0 545220 461792 6272 S 84.7 23.9 2:24.99 sysbench
。。。
|
1
2
3
4
5
6
| #perf top -p 4156 (sysbench进程号)
Samples: 50K of event 'cpu-clock:pppH', 4000 Hz, Event count (approx.): 8617272536 lost: 0/0 drop: 0/0
Overhead Shared Object Symbol
76.10% [kernel] [k] __inet_check_established
11.45% [kernel] [k] __inet_hash_connect
。。。
|
故障分析#
减少本地端口分配快速进入"状态":
1
| echo "60000 60010" > /proc/sys/net/ipv4/ip_local_port_range
|
使用tcpdump抓包查看
1
| tcpdump -i lo port 3306 -w server.pcap
|
kill mysql进程后可以看到,3306端口发送FIN要求主动关闭,客户端没有响应,并再次发查询时,mysql回复RST。

从后面抓一个包看下,systbench使用了新的本地端口60004重新发起请求,这是MySQL返回1159

1
2
| #perror 1159
MariaDB error code 1159 (ER_NET_READ_INTERRUPTED): Got timeout reading communication packet
|
mariadb发送 Greeting 10秒后,返回1159
1
2
3
4
5
6
| server/sql/sql_const.h
/*
Default time to wait before aborting a new client connection
that does not respond to "initial server greeting" timely
*/
#define CONNECT_TIMEOUT 10
|
客户端这种处理导致大量链接处于 CLOSE WAIT状态。
CLOSE WAIT状态:
被动关闭时出现的状态,当状态由ESTABLEISTED收到FIN时进入CLOSE WAIT状态, 被动关闭一方没有等待调用close()系统调用,出现此状态。此案例中是客户端未关闭。
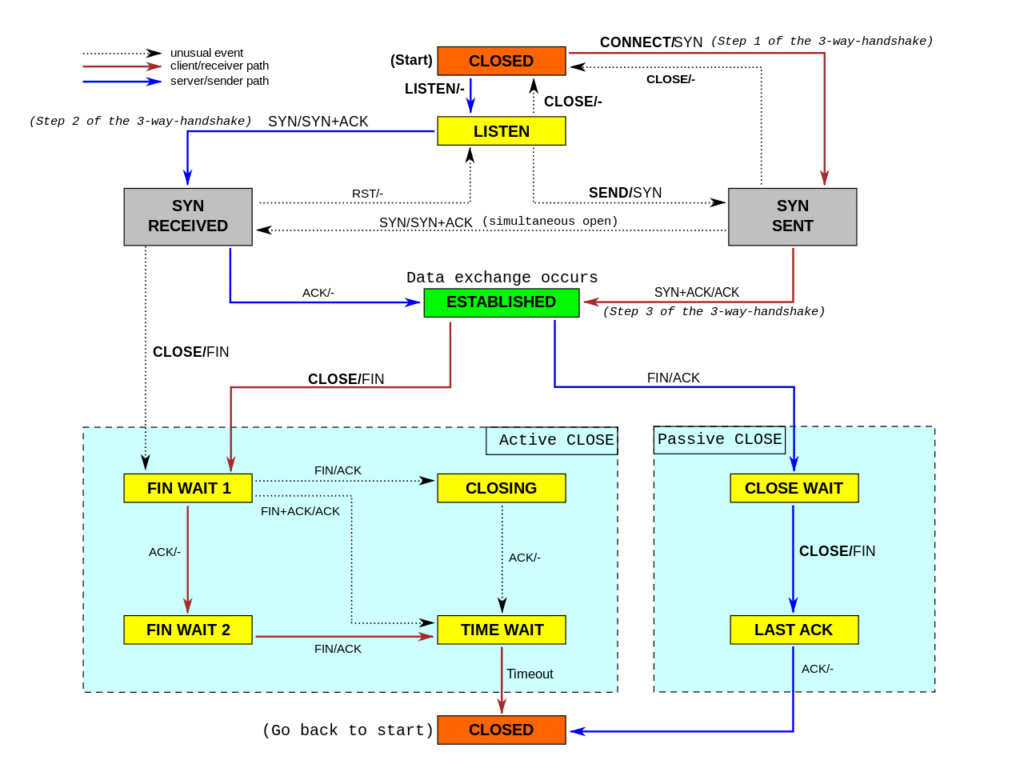
图片from wiki
Recv-Q
Recv-Q队列中有132字节数据待处理,这时的状态是CLOSE_WAIT。可以看到最后一个ACK报文中Ack = 133, 也就是在等待第133字节报文。那么前面已经收到了132字节数据。
man netstat 中对有Recv-Q的说明
1
2
3
4
5
6
7
| Recv-Q
Established: The count of bytes not copied by the user program connected to this socket. Listening: Since Kernel
2.6.18 this column contains the current syn backlog.
Send-Q
Established: The count of bytes not acknowledged by the remote host. Listening: Since Kernel 2.6.18 this column
contains the maximum size of the syn backlog.
|
Recv-Q计算方法#
http://blog.chinaunix.net/uid-20662820-id-3509532.html
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| //net/ipv4/tcp_diag.c
static void tcp_diag_get_info(struct sock *sk, struct inet_diag_msg *r,
void *_info)
{
struct tcp_info *info = _info;
if (inet_sk_state_load(sk) == TCP_LISTEN) {
r->idiag_rqueue = READ_ONCE(sk->sk_ack_backlog);
r->idiag_wqueue = READ_ONCE(sk->sk_max_ack_backlog);
} else if (sk->sk_type == SOCK_STREAM) {
const struct tcp_sock *tp = tcp_sk(sk);
r->idiag_rqueue = max_t(int, READ_ONCE(tp->rcv_nxt) -
READ_ONCE(tp->copied_seq), 0);
r->idiag_wqueue = READ_ONCE(tp->write_seq) - tp->snd_una;
}
if (info)
tcp_get_info(sk, info);
}
|
打印一下tp->rcv_nxt, tp->copied_seq 期待要接收的下一个序号,已经拷贝到用户的的序号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| [root@iZ8vbd88lmglnbsnad85q3Z bpf]# vi state.t
#include <linux/skbuff.h>
#include <linux/ip.h>
#include <linux/socket.h>
#include <linux/netdevice.h>
#include <linux/tcp.h>
BEGIN {
@tcp_stat[TCP_ESTABLISHED] = "TCP_ESTABLISHED";
@tcp_stat[TCP_SYN_SENT] = "TCP_SYN_SENT";
@tcp_stat[TCP_SYN_RECV] = "TCP_SYN_RECV";
@tcp_stat[TCP_FIN_WAIT1] = "TCP_FIN_WAIT1";
@tcp_stat[TCP_FIN_WAIT2] = "TCP_FIN_WAIT2";
@tcp_stat[TCP_TIME_WAIT] = "TCP_TIME_WAIT";
@tcp_stat[TCP_CLOSE] = "TCP_CLOSE";
@tcp_stat[TCP_CLOSE_WAIT] = "TCP_CLOSE_WAIT";
@tcp_stat[TCP_LAST_ACK] = "TCP_LAST_ACK";
@tcp_stat[TCP_LISTEN] = "TCP_LISTEN";
@tcp_stat[TCP_CLOSING] = "TCP_CLOSING";
@tcp_stat[TCP_NEW_SYN_RECV] = "TCP_NEW_SYN_RECV";
}
kprobe:tcp_set_state
{
// 1. 第一个参数是 struct sock
$sk = (struct sock*)arg0;
// 2. 获取struct tcp_sock
$tp = (struct tcp_sock *)($sk);
// 3. 打印 等待接收的下一个tcp段的序号 尚未从内核空间copy到用户空间的段最小的一个序号
printf("comm %d %s %s : rcv_ntx %lu copied_seq %lu\n", pid, comm, @tcp_stat[$sk->sk_state], $tp->rcv_nxt, $tp->copied_seq);
}
END{
clear(@tcp_stat);
}
|
参考链接 https://github.com/bpftrace/bpftrace/tree/master/tools
1
| bpftrace state.t | tee bpftrace.log
|
同时进行抓包
当时的疑惑点在 Server Greeting 77个字节, Response Error 1159 54个字节 , 131个字节,怎么Recv-Q显示是132呢? 后来翻到上面链接才看到这个值是一个差值,(等待接收下一个tcp序号 - 尚未从内核空间拷贝到用户空间的最小的序号)
Server Greeting 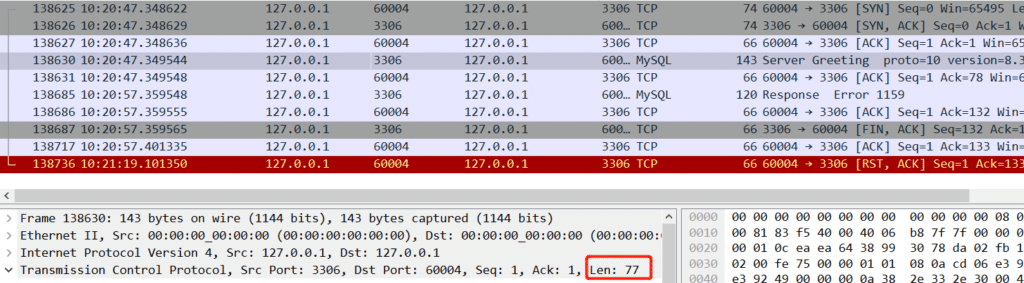 Response Error 1159
Response Error 1159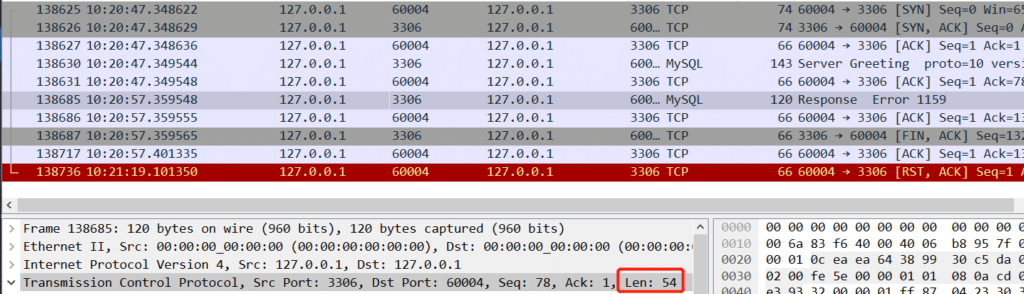
FIN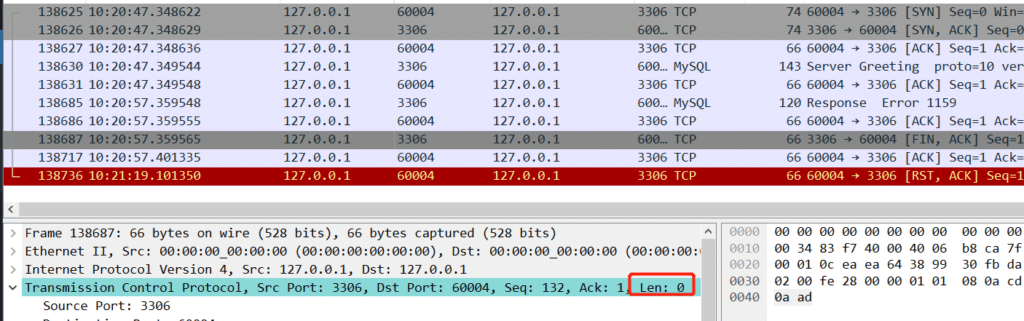
sysbench最后一个ACK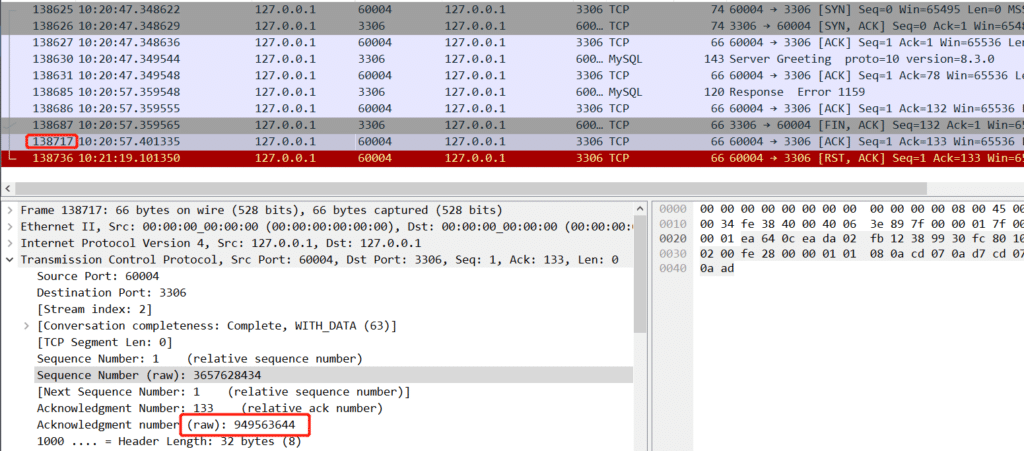
1
2
| # 对应的值
comm 7830 sysbench TCP_CLOSE_WAIT : rcv_ntx 949563644 copied_seq 949563512
|
往前找到949563512 ,Server Greeting 的报文开始序号。 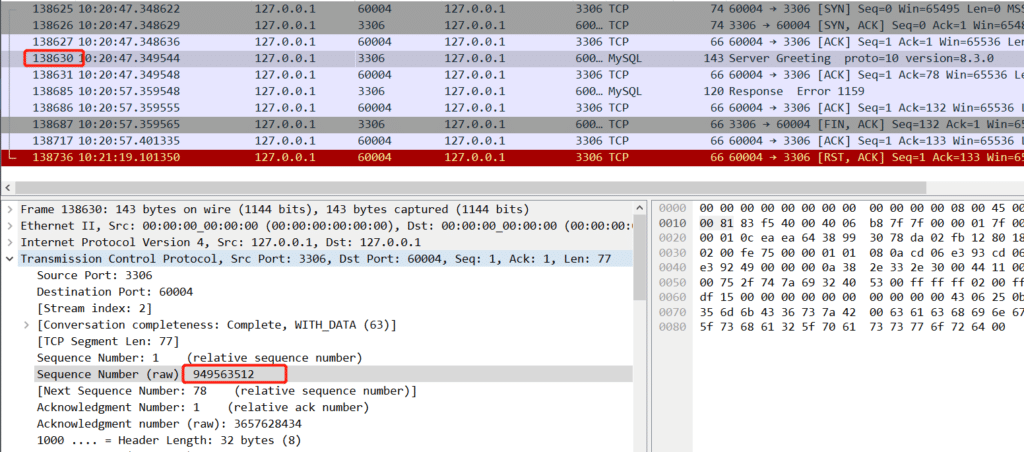
sysbench 一直再重连但是未发送mysql相关报文
相关故障处理方法:
https://www.ctyun.cn/developer/article/405333884604485
https://articles.zsxq.com/id_d27pgzmhuq08.html
https://github.com/akopytov/sysbench/pull/528
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| static int mysql_drv_reconnect(db_conn_t *sb_con)
{
db_mysql_conn_t *db_mysql_con = (db_mysql_conn_t *) sb_con->ptr;
MYSQL *con = db_mysql_con->mysql;
log_text(LOG_DEBUG, "Reconnecting");
DEBUG("mysql_close(%p)", con);
mysql_close(con);
mysql_init(con);
while (mysql_drv_real_connect(db_mysql_con))
{
if (sb_globals.error)
return DB_ERROR_FATAL;
usleep(1000);
mysql_close(con);
mysql_init(con);
}
log_text(LOG_DEBUG, "Reconnected");
return DB_ERROR_IGNORABLE;
}
|
ip_local_port_range#
/proc/sys/net/ipv4/ip_local_port_range
另外一个现象就是本地端口使用,ss -s tcp链接不停增长导致本地端口用尽。__inet_check_established
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| //net/ipv4/inet_hashtables.c
/* called with local bh disabled */
static int __inet_check_established(struct inet_timewait_death_row *death_row,
struct sock *sk, __u16 lport,
struct inet_timewait_sock **twp)
{
...
spin_lock(lock);
sk_nulls_for_each(sk2, node, &head->chain) {
if (sk2->sk_hash != hash)
continue;
// 四元组匹配
if (likely(inet_match(net, sk2, acookie, ports, dif, sdif))) {
if (sk2->sk_state == TCP_TIME_WAIT) {
tw = inet_twsk(sk2);
if (twsk_unique(sk, sk2, twp))
break;
}
goto not_unique;
}
}
...
not_unique:
spin_unlock(lock);
return -EADDRNOTAVAIL;
}
|
由于这个测试场景,源地址,目标地址,目标端口都是固定的, 那么只有源端口变化。所以当源端口用尽, 返回99
An application using the connect() call fails with an error code EADDRNOTAVAIL [99], 也就是mysql返回的那个返回码
最后发送的RST#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| bpftrace -e 'kprobe:tcp_send_active_reset {printf("kstack: %s\n", kstack);}'
kstack:
tcp_send_active_reset+1
tcp_close+317
inet_release+66
__sock_release+61
sock_close+17
__fput+150
task_work_run+92
do_exit+549
do_group_exit+51
get_signal+337
arch_do_signal_or_restart+236
exit_to_user_mode_loop+179
exit_to_user_mode_prepare+110
syscall_exit_to_user_mode+18
entry_SYSCALL_64_after_hwframe+97
|
手工终止sysbench后 通过bpftrace可以看到,在程序退出时如果有未处理的数据, 操作系统发送了RST包。
/net/ipv4/tcp.c
1
2
3
4
5
6
7
| /* As outlined in RFC 2525, section 2.17, we send a RST here because
* data was lost. To witness the awful effects of the old behavior of
* always doing a FIN, run an older 2.1.x kernel or 2.0.x, start a bulk
* GET in an FTP client, suspend the process, wait for the client to
* advertise a zero window, then kill -9 the FTP client, wheee...
* Note: timeout is always zero in such a case.
*/
|
1
2
3
4
5
| 2558 } else if (data_was_unread) {
2559 /* Unread data was tossed, zap the connection. */
2560 NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONCLOSE);
2561 tcp_set_state(sk, TCP_CLOSE);
2562 tcp_send_active_reset(sk, sk->sk_allocation);
|
不太熟悉bpf实现原理,这里tcp_close+317 定位到。
1
| 2600 sk_stream_wait_close(sk, timeout);
|
后面可以梳理一下tcp_close的处理流程
参考链接 https://www.iteye.com/blog/simohayha-503856
我正在「程序员案例分享圈」和朋友们讨论有趣的话题,你⼀起来吧?https://t.zsxq.com/18VYd8fPm
参考及引用#
http://blog.chinaunix.net/uid-20662820-id-3509532.html
https://www.ctyun.cn/developer/article/405333884604485
https://plantegg.github.io/2021/04/06/%E4%B8%BA%E4%BB%80%E4%B9%88%E8%BF%99%E4%B9%88%E5%A4%9ACLOSE_WAIT/
https://plantegg.github.io/2019/04/21/netstat%E5%AE%9A%E4%BD%8D%E6%80%A7%E8%83%BD%E6%A1%88%E4%BE%8B/
https://plantegg.github.io/2020/11/30/%E4%B8%80%E5%8F%B0%E6%9C%BA%E5%99%A8%E4%B8%8A%E6%9C%80%E5%A4%9A%E8%83%BD%E5%88%9B%E5%BB%BA%E5%A4%9A%E5%B0%91%E4%B8%AATCP%E8%BF%9E%E6%8E%A5/
图片from chatgpt