昨天正在听一位老师的英语的直播课, 当时她正在用影片的片段讲解英文听力课,讲到一半的时候,直播中断了。 显示“stream suspended for policy violations”
后来查了下资料才知道, 平台通过Connent ID系统的运作方式来识别和管理上传的视频和音频版权。 千亿美金的YouTube:收购后的13年里 Google做了什么?这篇文章比较详细的介绍了Google收购YouTube后, 对其版权管理和内容变现盈利模式做的一些工作。 Youtube的成功离不开 Google 长远的眼光,而“ Google的生态数据、广告销售体系和Google Cloud的支持,也放大了YouTube的商业价值。”
Content ID系统
Google收购Youtube后为解决其版权问题,建立一个能识别版权内容的Content ID系统。
版权所有者可以向YouTube上传自己的音频或视频文件,Content ID数据库根据这些文件来创建内容“指纹”。
如果发现有翻拍或模仿的内容,平台会给版权所有者三个选择:
- 禁播:禁止用户观看整个视频
- 获利:通过在视频中投放广告来利用视频获利;有时可以与上传者分享收益
- 跟踪:跟踪视频的观看情况统计信息
官网的一个视频介绍
实现思路及相关知识点整理
关于Content ID系统闭源实现, 目前没找到相关资料, 个人理解应该涉及三个方面。
- 视频识别
- 处理流程
- 服务整合
视频识别
视频识别主要涉及计算机视觉技术**(Computer Vision, CV),**涉及计算机视觉的基础模型,特征提取,近几年都受到深度学习的影响,出现了基于深度学习计算机视觉模型。
计算机视觉
- 概念
计算机视觉通过模仿人类的视觉系统,从照相机,摄影机等视频采集设备中获取原始信息,通过这些原始信息,进行语义(Semantic)解释或者逻辑理解。比如我们使用的电脑,我们需要识别显示器, 键盘,鼠标,并在头脑中形成这些物体的概念。
- 领域特点
**跨学科领域:**计算机视觉涉及多个领域
- 生物学领域:人眼及视觉神经系统,理解人脑的处理机制
- 物理学领域:设备越精密,越能完整的额捕获外界信息,主要涉及光学领域的研究。
- 计算机科学:信息检索,计算机体系结构,机器学习。
- 生物学领域:人眼及视觉神经系统,理解人脑的处理机制
相关难题:
- 图像信息与语义之间巨大鸿沟。例如:如何将一个200*200RGB图像,对应12万数字组成的矩阵与具体的事物关联起来。
- 识别速度。实验表明,一副普通场景图片,人类需要150毫秒,人类在理解图片时,依靠过去的记忆、经验、外界知识来对图像中物体进行判断。这些都是计算机系统难以企及的。
- **实现方式。**是模仿人类视觉系统还是需要开辟其他研究道路。
- 应用:
视频识别已经在人脸识别,光学字符识别,电影特效,视觉搜索,自动驾驶,无人商店,虚拟现实,增强现实等方面有了广泛应用。
- 基础模型及操作:
像素表达:
根据不同的图像类型像素表达也不同.
- 黑白图像:转化0或1的二元矩阵
- 灰度图像:每一个像素代表灰度的“强度”Intensity 范围在0-255
- 彩色图像:比较流行的RGB,三种颜色叠加,RGB代表三种不同的通道,每一个通道都是一个矩阵表达,每个像素代表0-255,彩色图像是一个**张量(Tensor),**也就是三个矩阵叠加一起的结果。
- 黑白图像:转化0或1的二元矩阵
像素本身是真实世界中的“采样”,连续的信号采样到离散像素,难免会有失真的情况,不同分辨率会有不同程度的像素表达。
关键字 Pixel
过滤器:
- 移动平均(Moving Average)
这个过滤器的本质就是针对每个像素点对周围的9个像素点,计算其平均值,并形成心得矩阵。然后对新像素点视觉化。
- 卷积(Convolution)
是透过两个函数_f_和_g_生成第三个函数,表示函数_f_与经过翻转和平移的_g_的乘积函数所围成的曲边梯形的面积。
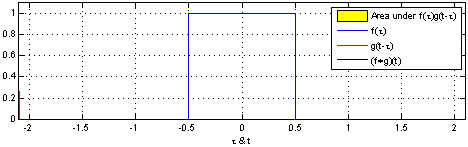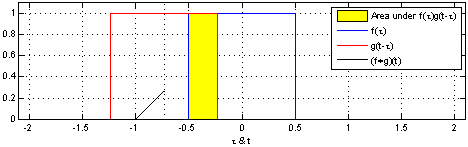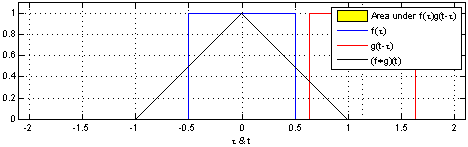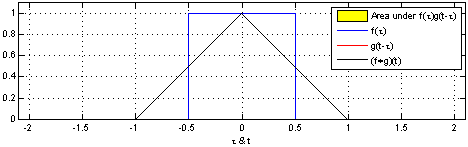

from wiki https://zh.wikipedia.org/wiki/%E5%8D%B7%E7%A7%AF
关键字:Filter
边界探测:
在数学分析中通常通过倒数或者梯度来表示函数变化的信息。一个好的边界探测除了能够探测边界外还需要尽可能的使边界平滑和链接。
关键字;Edge Detection
- 特征提取:
计算机要实现对图像的语义理解, 通过对图像的抽象然后并在此特征基础上进行建模,并且可以结合其他信息,如文字进行理解和分析。常见的形式是图像和一段文字结合起来。
特征提取基本思路:局部信息(Local Information), 在诸多变化特征中找到不变的成分。
- 找到一组关键点或是像素;
- 关键点周围定义一个区域;
- 抽取并且归一化这个区域;
- 从归一化后区域提取局部描述子(Local Descriptor)。
- 找到一组关键点或是像素;
从局部找具体代表性特征, 然后把各种因素造成的特征变化归一化掉。
深度学习构造描述子的方法:SIFT(Scale-invariant feature transform), HOG(Histogram of oriented gradient)
- 深度学习:
通过深度学习可以挖掘数据中的非线性关系, 传统机器学习早期是寻找**特征, 特征工程(Feature Engineering),**常用模型:
- 树模型
- 概率图模型
- 树模型
存在问题:不具有不普适性,模型都需要单独训练,计算复杂。
所有需要找到一种方法自动挖掘数据背后的隐含规律,并且不同模型可以共用同一套计算框架,深度学习技术刚好可以解决以上问题。深度学习最简单最基础的模型
- 深度神经网络
深度神经网络在足够内部隐含变量的情况下可以表达任意复杂的函数关系, 并且具有普适性。
- 深度神经网络模型
- 前馈神经网络(Feedforward Networks):通过Sigmoid激活函数和线性整流函数,对线性模型输出进行非线性变换。
- 卷积神经网路(Convolutional Neural Networks): 使用向量来描述一个矩阵信息, 通过卷积和池化提取图片的关键特征。
- 深度学习模型优化
一般机器学习:模型是一组特征,可以表示为一个数学模型, 目标函数是构造参数的方法,模型参数获取过程叫做模型训练或模型优化, 根据目标函数找到最优解。一般使用梯队下降法求解参数, 理论上针对凸问题(Convex Problem)可以找到全局最优解,但是非凸问题仅能收敛到局部最优解。
深度学习:同样需要对一个目标函数进行有效学习, 深度模型多层的结构和高度的非凸性,使其很难获得一个全局最优解。好的初始值往往能够让优化过程变得容易一些。
- 视觉领域深度学习模型
- AlexNet:
- VGG 和 GoogleNet:
- ResNet
学习模型的发展趋势就是加深网络层次, 优化网络架构
视觉领域高级话题
- 图像物体识别和分割
R-CNN ,Fast R-CNN,Faster R-CNN, Mask R-CNN每一个模型都在前一个模型基础上进行优化
- 视觉问答
需要对图片细节,上下文进行理解,并对图像物体进行推断。
基础模型:针对问题,图片标题,模型进行“词包”表达,VGG 网络来提取图片的特征。
另外可以利用LSTM把问题和图像结合到一起进行问答预测。
- 产生式模型
模型能够产生数据。可以通过概率图模型,针对复杂数据可以考虑使用产生式对抗网络模型,通过产生器产生数据和判别器判断数据真伪知道无法判断真伪为止。从而达到数据以假乱真的效果。
处理流程
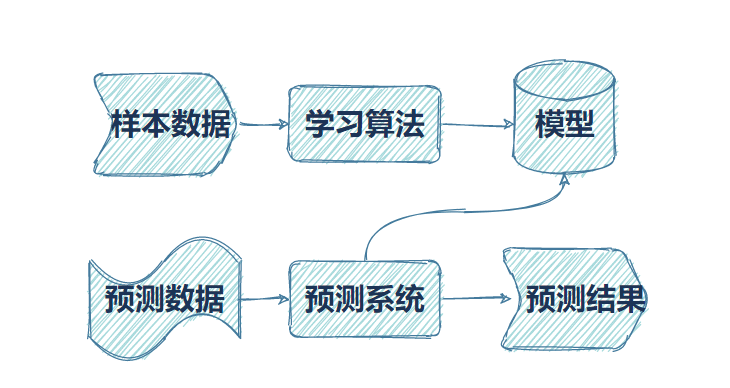
服务整合
版本所有者在youtube系统将样本数据提交“content id系统”生成算法模型,视频发布者或者直播播主的视频、视频流通过预测系统调用模型, 返回一个预测结果判断是否侵权。对于预测结果会设定匹配阈值,超过阈值则认为涉及侵权,进行后续处理。
参考及引用
Photo by Quang Nguyen Vinh from Pexels
极客时间 洪亮劼《AI技术内参》