File Searching Using Variable Length Keys
最早提及Trie树的一篇文章
MANY computer applications require the storage of large amounts of information within the computer’s memory where it will be readily available for reference and updating. Quite commonly, more storage space is required than is available in the computer’s high-speed working memory. It is, therefore, a common practice to equip computers with magnetic tapes, disks, or drums, or a combination of these to provide additional storage. This additional storage is always slower in operation than the computer’s working memory and therefore care must be taken when using it to avoid excessive operating time.
许多计算机应用程序需要在存储内的大量信息。通常,外存需求量要大于内存,高速缓存。因此,为计算机配备磁性设备的常见做法磁带,磁盘或鼓,或这些的组合提供额外的存储空间。这个额外的存储空间是总是比计算机的运行速度慢,因此在使用存储时必须小心避免过多的操作时间。
This paper discusses techniques for use in locating records stored within a low-speed memory medium where they are identifiable by a key word or words of variable length on a machine not equipped to accomplish this automatically. The technique is also applicable to the conversion of variable word length information into fixed length code words.
本文讨论了用于在低速存储介质中定位记录的技术, 可以用一个或多个关键词识别。 该技术也适用于将可变字长信息转换为 固定长度的代码字。
When records can be stored in a slower memory medium in such a fashion that their exact location may be determined from the nature of their designation, reasonably efficient handling procedures can be established. However, as is often the case, the records cannot be so easily located and it becomes necessary to examine each entry in order to locate a particular record. Sequential examination of the key words of each record, until the desired record is located, is not a satisfactory approach on machines not having automatic buffered searching facilities, and may not be satisfactory on machines so equipped, if, for instance, reels are searched which need not be because it is not known in advance that they are not needed. Because the average search time for the desired records is proportional to the number of records stored in this slower memory, the total operating time of a program is proportional to the product of the number of records stored and the number of records for which search is instigated. This product may approach the square of the number of records involved. This relationship between operating time and the number of records stored places a definite limitation on the number of records which may reasonably be stored by any particular program. Fortunately, if the records can be stored with the key words in some ordered arrangement, an educated guess can then be made as to the location of a particular record, and a better system will result. However, records cannot always be arranged in such a fashion.
我们可以通过一些专门设计的方法或处理程序访问存储在较慢的存储介质中的数据。但是,通常情况下,记录不容易定位,因此有必要检查每个条目访问地址。在没有自动缓冲搜索功能的机器上,对每个记录的关键字进行顺序检查,直到找到所需的记录,都不是令人满意的方法,例如,如果搜索卷轴,则不必这样做,因为事先不知道不需要这些卷轴。因为所需记录的平均搜索时间与记录数量成正比,所以程序的总运行时间与存储的记录数量与要进行搜索的记录数量的乘积成正比 。 该乘积可能接近所涉及记录数的平方。 操作时间与存储的记录数之间的这种关系对可以由任何特定程序合理存储的记录数有一定的限制。 幸运的是,如果可以将关键字与关键字以某种有序的方式存储在一起,则可以对特定记录的位置进行有根据的猜测,从而得到更好的系统。 但是,记录不能总是以这种方式排列。
When records are large compared to the key word or words, a useful technique is to form an index having in it just the key words and the location on the corresponding record. A particular record is then located by searching the index to determine the record’s location and then taking the most rapid approach in arriving at the record. Since only the key words and the locations of the corresponding records are stored in the index this technique reduces the amount of information which must be handled during a search. With the smaller amount of information involved it is often possible to utilize the computer’s high-speed memory for the storage and searching of the index. Furthermore, this index can now be ordered or otherwise subjected to speed-up techniques. This index approach often can greatly improve the operating efficiency of record handling programs. In many instances this improvement is sufficient but there are also many cases where a further increase in efficiency is necessary. In particular, the time required to perform the search when consulting the index may still be objectionably large. If this is true then it is necessary to apply a speed-up technique to the searching operation. Of course these techniques can be applied to any table lookup problem where the nature of the key word or words does not lead directly to the desired entry.
当记录比一个或多个关键词大时,一种有用的技术是形成一个索引,其中仅包含关键词和相应记录上的位置。然后,通过搜索索引来确定特定记录的位置,从而找到特定记录,然后采用最快的方法来获得该记录。由于仅关键字和相应记录的位置存储在索引中,因此该技术减少了在搜索过程中必须处理的信息量。由于涉及的信息量较小,通常可以利用计算机的高速存储器来存储和搜索索引。此外,该索引现在可以排序或以其他方式使用加速技术。这种索引方法通常可以大大提高记录处理程序的运行效率。在许多情况下,这种改进是足够的,但在许多情况下,还需要进一步提高效率。特别是,查询索引时执行搜索所需的时间可能仍然过长。如果是这样,则有必要对搜索操作应用加速技术。当然,这些技术可以应用于任何一个或多个关键字的性质不直接导致所需条目的表查找问题。
Peterson 1 has suggested a method of arranging such an index which greatly reduces the lookup time when it can be applied. This method, referred to as the “bucket method,” calls for randomizing the digits of the key word to produce a number which indicates that point in the available memory where a particular key and its corresponding record location should be stored. If this particular space is not available it is stored in the next highest (or lowest) available space. When seeking a particular record, the exact randomization process is repeated producing the same indicated point and a search is begun from that point in memory and in the previously used direction. When using this method, facility must be provided to continue from the other end when one limit of the available space is reached. During the process of placing an entry in this table a record is kept of the number of steps which must be taken before finding space to store the entry. This number is then compared with and, if necessary, replaces the previously occurring maximum. This maximum can then be used to limit the operation when a search is undertaken for an item for which there is no entry
彼得森(Peterson)提出了一种安排这样的索引的方法,该方法可以在可应用时大大减少查找时间。该方法称为“存储桶方法”,它要求将关键字的数字随机化以产生一个数字,该数字指示可用存储器中应存储特定关键字及其对应记录位置的那个点。如果此特定空间不可用,则将其存储在下一个最高(或最低)可用空间中。当查找特定记录时,重复精确的随机化过程以产生相同的指示点,并从该点开始在存储中并沿先前使用的方向进行搜索。使用此方法时,必须提供设施,以便在达到可用空间的一个限制时从另一端继续。在将条目放置在此表中的过程中,会保留一条记录,其中记录了在找到存储条目的空间之前必须执行的步骤数。然后将该数字与之比较,并在必要时替换先前出现的最大值。然后,当搜索没有条目的项目时,可以使用此最大值来限制操作
https://dl.acm.org/doi/10.1145/321172.321178 关于bucket method的方法描述, Peterson叫他open-addressing system, 数据的存储分为一下几个步骤: 1. 为每个要归档的记录计算一个地址; 2. 检查存储桶中可以存放数据的第一个单元(cell), 将记录存入 3. 如果这个单元不为空,那就继续检查,第二个单元格, 第三个单元格, 第n个单元格, 并将记录存入 4. 如果所有单元格已满, 增加一个cell到bucket重复2,3 5. 如果bucket没有了空闲的cells再增加一个,通过查找将记录存入 **由于后面论文内容没有权限, 无法知道记录是怎么分到到不同侧cell中,我理解可以用一致性hash的思路 通过一个运算将记录均匀分散到不同的bucket/cell中, cell分布在不同bucket中,bucket就类似一致性hash的物理节点 cell可以理解为虚拟节点。当节点达到一定数量是就可以实现均匀分布和快速存取。 当然也可以分布式存储,就是一致性hash的实现了。
The object of this procedure is to distribute the records evenly throughout the available space in spite of uneven characteristics which occur because of similarities in the structure of the keys. A limitation of this method is that it is necessary to store the key as a part of the entry in order to identify an item positively during the searching phase. This increases the storage space used and, as the memory fills up, the average number of spaces which must be examined before an entry is located increases. This saturation effect greatly decreases the operating efficiency. Furthermore, this method becomes far too involved from the bookkeeping standpoint when the keys are variable word-length words which exceed the length of one computer word when working with a fixed word-length machine.
该过程的目的是尽管由于键的结构相似而出现不均匀的特性,但仍将记录均匀地分布在整个可用空间中。 该方法的局限性在于,有必要将关键字存储为条目的一部分,以便在搜索阶段正确地标识项目。 这会增加使用的存储空间,并且随着存储的填满,条目进入之前必须检查的平均空间数会增加。 这种饱和效应大大降低了工作效率。 此外,当键是可变字长的单词,当使用固定字长的机器工作时,该可变字长的单词超过一个计算机字的长度时,该方法从记录的角度来看变得太复杂。
https://www.computerhistory.org/timeline/1956/ 计算机的发展史 1959年前后的计算机
When it is necessary to have some method of determining whether any given word has occurred previously, sequentially scanning the previous entries is impractical because of the limitations mentioned previously. A more desirable situation would be a scheme that in no way depended upon the amount of previously stored information in the file. If this could be accomplished, the operating time would then be more nearly proportional to the number of items for which a search was performed rather than the product of this number and the total number of entries in the file.
当需要某种确定先前是否出现过任何给定单词的方法时,由于前面提到的局限性,顺序扫描先前的条目是不切实际的。 更理想的情况是一种方案,该方案决不取决于文件中先前存储的信息量。 如果能够做到这一点,那么操作时间将与执行搜索的项目数成比例,而不是该数量与文件中条目总数的乘积。
The technique we have developed accomplishes the goal. The operating time is related to each letter of the external word and is, therefore, proportional to the number of letters in each word for which a search is performed. The size of the file has little effect on the operating time. Total operating time is proportional to the number of external words multiplied by the time required for a word of average length.
我们开发的技术可以达到目标。 操作时间与外部单词的每个字母有关,因此,与每个单词中要执行搜索的单词的数量成比例。 文件的大小对运行时间影响很小。 总操作时间与外部单词数乘以平均长度的字所需的时间成正比。
Trie树的时间复杂度就就是所有单词的长度的和和这个word和平均长度乘积一致。
In our particular application each external name becomes a record which is stored on tape-. The location of the first word of each record is the code for that external word. The external word itself is the key. In the computer’s main (drum) memory we form an index of the key and its corresponding code. The organization of this index is the reason for this method’s efficiency. We call this the “letter tables” method. The index consists of a set of tables with the number of tables as well as the number of en tries in each table varying with each running of the program. An address, usually the lowest numbered available cell, is assigned as the starting point of the table of first letters. The key words are examined letter by letter and each first letter which occurs is entered in the table of first letters if such an entry does not already exist (Fig. 1). A new table is assigned to each of these letters. It is formed by assigning it a starting address. Each second letter which occurs is entered in the table assigned to the letter which it follows. To each of these second letter entries a new table is assigned as before. Each third letter is placed in the table assigned to the letter pair which it follows. Thus, there will be a table for the letters which follow “CA” and a different table for those letters which follow “CB” if these combinations occur. To each third letter a table is assigned and the technique is repeated until all letters of the key have been taken care of.
在我们的特定应用程序中,每个外部名称都将成为一条记录,并存储在磁带上(tape)上。每个记录的第一个单词的位置是该外部单词的代码。外来词本身就是关键。在计算机的主(磁鼓drum )存储器中,我们形成按键及其对应代码的索引。该索引的组织是此方法高效的原因。我们称其为“字母表”方法。该索引由一组表组成,表的数量以及每个表中的条目数随程序的每次运行而变化。地址(通常是编号最小的可用单元格)被分配为首字母表的起点。逐个字母地检查关键字,如果尚无这样的条目,则将每个出现的第一个字母输入到第一个字母表中(图1)。新表分配给这些字母中的每个字母。它是通过为其分配一个起始地址而形成的。出现的每个第二个字母都输入到分配给其后一个字母的表中。像以前一样,为每个第二个字母条目分配一个新表。每个第三个字母都放在分配给其后的字母对的表格中。因此,如果出现这些组合,将存在一个表,用于在“ CA”之后的字母,并为在“ CB”之后的字母提供不同的表格。对于每个第三个字母,分配一个表,并重复该技术,直到密钥的所有字母都已处理完毕为止。
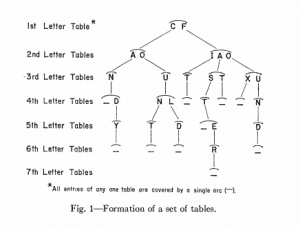
In our program the words which make up a key are compressed to eliminate blank spaces before being placed in the table as one word. A blank space is then used to signify the end of the word. This blank space is stored in the set of tables as a signal that the entry is complete and the code word which was previously determined is stored with this blank instead of an indication of a table assigned for the next letter. If preservation of the blanks is n necessary, a special unique mark may be used to signal the end of a key.
在我们的程序中,构成键的单词被压缩以消除空格,然后将它们作为一个单词放入表格中。 然后使用空格来表示单词的结尾。 该空白存储在表集中,作为输入已完成的信号,并且先前确定的代码字与该空白一起存储,而不是指示分配给下一个字母的表。 如果不需要保留空白,则可以使用特殊的唯一标记来表示键值已结束。
Trie结构中的结束的标识
When attempting to determine the previous occurrence of a particular word the procedure is first to scan the table of first letters until the desired letter is found. The second letter is then compared with the various entries in the assigned table until agreement is found for the second letter. The third letter is compared in a similar manner with the indicated table and the process is continued until comparison occurs with a blank. When this occurs the desired code may be found in the remainder of the entry with that blank. In the event that the desired letter does not occur in a particular list, it is known that this~-word is not in the index. If this word is to be added, it is now necessary to store the remaining letters of the word in the index using the previously described technique. The first letter to be added will be the one which did not occur. Once a letter has been added to the tables there are no entries in the newly formed table so no further searching is necessary, and it is only necessary to add each letter remaining in the word to the new tables.
当尝试确定特定单词的先前出现时,该过程首先扫描第一个字母的表,直到找到所需的字母。然后将第二个字母与分配表中的各个条目进行比较,直到找到第二个字母的一致。将第三个字母与指示的表以类似的方式进行比较,然后继续该过程,直到比较结果为空白为止。发生这种情况时,可以在条目的其余部分找到所需的代码,并留空。在特定列表中未出现所需字母的情况下,已知此单词不在索引中。如果要添加此单词,则现在必须使用先前描述的技术将单词的其余字母存储在索引中。要添加的第一个字母将是未出现的字母。将字母添加到表后,新形成的表中将没有任何条目,因此无需进一步搜索,只需将单词中剩余的每个字母添加到新表中即可。
As previously mentioned, the code is stored with the blank which signifies the end of the word. This code is the next available location for a record in the external language file. As soon as the index is complete the external word, which is this next record, is placed in the file. The location indicator is adjusted to indicate the next available space in this file and this determines what the next code word will be.
如前所述,代码存储有空格,表示单词的结尾。 此代码是外部语言文件中记录的下一个可用位置。 一旦索引完成,则将下一个记录即外部单词放入文件中。 调整位置指示符以指示此文件中的下一个可用空间,并确定下一个代码字将是什么。
Since the amount of space required for any of the tables in this type of operation depends upon the manner in which the letters happen to follow each other, it becomes necessary to assign space to each of the tables as it is needed. This is best done by assigning the next available space to whichever table is being expanded. The programming principles involved in this type of operation were first described by Newell and Shaw.2 However, since in our application it is not necessary to remove en tries from the tables as was the case in their application, a less involved method than the one they described can be applied. If a continuous portion of memory can be devoted to the storage of the tables it can be utilized in a sequential fashion with the next available space being the next cell. A simple counter can then be used to keep track of this next available space. This operation results in the storage of the various tables in an overlapping fashion and, therefore, it is necessary that each entry in a table have an indication of the location of the next entry in that table.
由于在这种类型的操作中任何表所需的空间量取决于字母彼此紧跟的方式,因此有必要根据需要为每个表分配空间。最好通过将下一个可用空间分配给正在扩展的表来完成。这种类型的操作所涉及的编程原理首先由Newell和Shaw进行了描述。但是,由于在我们的应用程序中,不必像在应用程序中那样从表中删除表项。如果可以将存储的连续部分专门用于表的存储,则可以以下一个可用空间为下一个单元的顺序方式使用它。然后可以使用一个简单的计数器来跟踪下一个可用空间。该操作导致以重叠的方式存储各种表,因此,表中的每个条目都必须指示该表中下一个条目的位置。
单独有一个空间存储表,并且可以连续操作
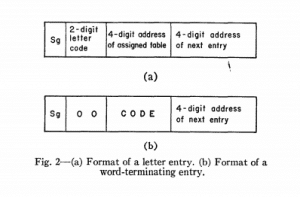
Fig. 2 shows the two types of entries in these tables. The letter entry shown in Fig. 2(a) has the letter in the two digits on the left end of the word, and the four digits on the right end are used for the address of the next entry in this table. The remaining four digits specify the address of the first word in the assigned table。
图2显示了这些表中的两种类型的条目。 图2(a)所示的字母条目在单词的左端有两位数字的字母,而在右端的四位字母是该表中下一个条目的地址。 其余四位数字指定分配表中第一个单词的地址。
Fig. 2(b) shows the configuration used for the storage of a blank which signifies the end of a word. In this word, the first two digits are blank, the next four digits are the code, and as in the previous case, the last four digits indicate the address of the next entry. The end of a particular list is signified by the absence of an address indicating the next entry.
图2(b)示出了用于存储表示单词结尾的空白的配置。 在此单词中,前两位为空白,后四位为代码,和前一种情况一样,后四位表示下一个条目的地址。 特定列表的结尾通过缺少指示下一个条目的地址来表示。
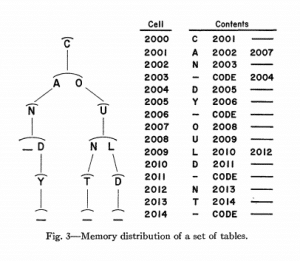
Fig. 3 shows a memory distribution which would result from the storage of the four words: can, candy, count, and could. In this example there are a total of twelve separate tables stored in the fifteen spaces. Although the system may appear more complicated, no more bookkeeping is required than in a system of sequentially searching a list of entries where the different entries require different numbers of words in memory for their storage.
图3显示了一个存储分布,它是由以下四个词的存储产生的:can,candy,count,could。 在此示例中,在十五个空间中总共存储了十二个单独的表。 尽管该系统可能看起来更加复杂,但是与顺序搜索条目列表的系统相比,不需要进行更多的bookkeeping工作,在该系统中,不同条目需要在存储器中存储不同数量的单词。
bookkeeping 是金融领域交易记录的,企业会计流程一部分, 不确定当时的电脑应用的开发是否和金融也有关系
An additional time-saving feature that can be applied with a slight additional cost of memory space is the establishment of a full set of possible first letters with the corresponding second letter tables assigned starting points. By this we mean that if the first letter is “£” the first en try in the assigned second letter table will be in the fifth cell with respect to the beginning of the tables. Those first letters which do not occur are then wasting one memory word each.
建立可能的第一个字母的完整集合,并为相应的第二个字母表分配起点,增加了一些附加空间但是节省了时间。 我们的意思是,如果第一个字母为“£”,则分配的第二个字母表中的第一个条目将相对于表的开头位于第五个单元格中。 然后,那些没有出现的前几个字母每个都浪费一个存储空间。
空间换时间
Since in this scheme there is only one letter stored in each word, it requires far more space than other schemes where several letters are stored in one word. However, the advantage in scanning speed makes up for this disadvantage and it becomes practical to form several tables of this type, storing them in a slower memory medium until needed. When doing this, difficulty can arise if care is not taken to avoid excessive transfers to and from this slower memory. Methods of overcoming this problem depend upon the particular application. In our application each set of tables is no longer needed after one complete pass of the input, and when overflow of space occurs, during input, those words which cannot be converted are marked. After completion of the first input pass the set of letter tables is erased and a second input pass begins at that point in the input data where overflow occurred. A new set of tables is formed to convert the marked words and the process can be repeated as often as necessary.
由于在该方案中每个单词中仅存储一个字母,因此与在一个单词中存储多个字母的其他方案相比,它需要更多的空间。但是,扫描速度的优势弥补了这一劣势,形成一些这种类型的表并将它们存储在较慢的存储介质中直至需要变得可行。这样做时,如果不注意避免往返于此较慢存储过多传输,则会出现困难。解决此问题的方法取决于特定的应用。在我们的应用程序中,在完整输入一次输入后就不再需要每组表,并且在输入期间发生空间溢出时,会标记那些无法转换的单词。在完成第一个输入遍之后,将擦除字母表集合,并在输入数据中发生溢出的那一点开始第二遍输入。形成了一组新表来转换标记的单词,并且可以根据需要重复执行该过程。
使用场景一次输入后不再需要了
Now let us look more closely at the technique in an effort to determine the operating time. For the sake of the following discussion, we shall assume each character to be one of 40 possibilities. This list of possibilities could include the 26 letters of the alphabet, ten decimal digits, a blank, and three special characters. The maximum number of comparisons necessary to determine a word then comes to 40 for each character in the word including the blank which terminates the word. We find however that this maximum is seldom reached. To show this, let us assume a file contains 1000 words. If the first characters of these words are evenly distributed among the 40 possibilities there will be approximately 25 words starting with each character. Since 25 words can provide only five-eighths of the possible entries in the second letter tables we can expect that to determine a word, the average number of comparisons needed will be 20 to determine the first letter, 13 to determine the second letter, and thereafter only one per letter. Thus a nine-letter word including the blank might require an average of approximately 40 comparisons.
现在让我们更加仔细地研究该技术,以确定运行时间。为了下面的讨论,我们将假定每个字符都是40种可能性之一。此可能性列表可能包括26个字母,十个十进制数字,一个空白和三个特殊字符。然后,对于单词中每个字符(包括以单词结尾的空格),确定单词所需的最大比较数达到40。但是,我们发现很少达到此最大值。为了说明这一点,我们假设一个文件包含1000个单词。如果这些单词的第一个字符在40个可能性中均匀分布,则从每个字符开始将大约有25个单词。由于25个单词只能提供第二个字母表中八分之五的可能条目,因此我们可以预期确定一个单词,确定第一个字母所需的比较平均次数为20个,确定第二个字母所需的比较次数为13个,并且此后每个字母只发送一个。因此,一个包含空白的9个字母的单词可能需要平均进行40次比较。
Now we increase the number of words to 10,000 and we find that we have an average of 250 words per character in the first letter table, 62t per character in the second letter tables, and approximately one and onehalf in the third letter tables. The average number of comparisons for a nine-letter word now comes to 20 for each of the first three letters and one for each of the remaining letters. This new total of 66 is 1.65 times greater than the previous average.
现在我们将单词数增加到10,000,我们发现在第一个字母表中每个字符平均250个单词,在第二个字母表中每个字符平均62t,在第三个字母表中大约每个字符一半。 现在,前三个字母的比较结果为9个字母,平均比较次数为20个,其余每个字母比较结果为1个。 这个新的总数为66,是以前平均水平的1.65倍。
When the words stored in such a fashion are taken from some formal language such as English, the number of words beginning with certain characters tends to increase and, therefore, the possibility of having all of the various characters occur in the table of first letters is decreased. This decreases the average number of comparisons needed to determine the first letter. Furthermore, the number of letters which normally might follow a particular letter is limited so that the average number of comparisons is reduced for subsequent letters also.
当以这种方式存储的单词取自某种正式语言(例如英语)时,以某些字符开头的单词数量趋于增加,因此,在首字母表中出现所有各种字符的可能性是减少了。 这减少了确定第一个字母所需的平均比较次数。 此外,通常可能跟随特定字母的字母的数目受到限制,从而也减少了随后字母的平均比较数目。
重复的越多的话,可以减少比较操作
For example we normally expect “U” to fol1ow “Q” and one of the vowels or the letters “H,” “L,” “R,” or “y” to follow the letter “C.” Thus we find we are able to adjust favorably the averages we determined previously due to bunching, a phenomenon which usually leads to decreased efficiency in other methods. In the instance of the 10,000-word file we might expect the averages to be more like 16, 12, 8, 3, and one thereafter which would be 44 for the nine-letter word, an improvemen t of one-third.
例如,我们通常期望“ U”跟在“ Q”之后,并且元音或字母“ H”,“ L”,“ R”或“ y”之一跟随字母“ C”。 因此,我们发现由于聚类,我们能够很好地调整先前确定的平均值,这种现象通常会导致其他方法的效率降低。 在10,000字的文件实例中,我们可能期望平均数更像16、12、8、3,此后的9个字母的平均数将为44,提高三分之一。
We shall now attempt to compare this technique with Peterson’s “bucket method.” The bunching which we described as useful to us must be overcome when using the “bucket method.” This is usually done by generating a number which is influenced by all characters of the word and yet appears to be random with respect to them. This is extremely difficult when dealing with variable word length information, especially with long words where only one letter differs or where the letters are the same but two have been interchanged. Other difficulties encountered with the “bucket method” include terminating the search when enough entries have been examined to know that the word is not in the file and then finding suitable space to insert the word. The resultant bookkeeping can actually consume many times more operating time than the actual comparison operation requires. Thus, although fewer comparisons may be required when using the “bucket method,” due to the variable word length problems, the operating time is pushed up into the same range as that of the “letter tables method” which we have described.
现在,我们将尝试将该技术与Peterson的“桶方法”进行比较。使用“存储桶方法”时,必须克服我们认为对我们有用的成束现象。通常,这是通过生成一个数字来完成的,该数字受单词的所有字符影响,但相对于它们似乎是随机的。当处理可变的字长信息时,尤其是对于只有一个字母不同或两个字母已互换但相同的长字,这尤其困难。 “存储桶方法”遇到的其他困难包括:在检查了足够多的条目以知道单词不在文件中时终止搜索,然后找到合适的空间插入单词。结果,bookkeeping实际上会消耗比实际比较操作所需时间多很多倍的操作时间。因此,尽管在使用“桶方法”时可能需要较少的比较,但是由于可变的字长问题,操作时间被推到与我们已经描述的“字符表方法”相同的范围内。
bookkeeping我理解作者的意思是落盘,不知道这个和当时的磁带和磁鼓有没有关系, 有点像录制的意思
Another way in which the two methods must be compared is with regard to the amount of memory required for the storage of similar amounts of information. In a fixed word length machine up to all but one character might be wasted with each word stored when using the “bucket method.” Also, when a minimum of two adjacent cells are used, one for the word and one for the code, an occasional word will be lost due to storage of a word requiring an odd number of cells in such a position as to leave only one unused cell between itself and an adjacent entry. The amount of memory space required for the storage of a particular amount of information in the “letter tables method” cannot be specifically determined because it is quite dependent upon the number of repetitions of letter sequences which occur. The number of cells required will always be greater than the number of words and may in some instances approach the total number of characters stored. This means that the “letter tables method” will probably require from two to six times as much memory space as the “bucket method” for a similar amount of information.
必须比较这两种方法的另一种方式是关于存储相似信息量所需的存储空间。在固定字长的机器中,使用“存储桶方法”时,存储的每个单词最多浪费一个字符。同样,当至少使用两个相邻的单元时,一个用于该单词,一个用于代码,由于存储需要奇数个单元的单词而在一个位置上仅留下一个未使用的位置,偶尔的单词将丢失自身与相邻条目之间的单元格。无法具体确定“字母表方法”中存储特定信息量所需的存储空间量,因为它完全取决于出现的字母序列的重复次数。所需的单元格数量将始终大于单词的数量,并且在某些情况下可能接近所存储字符的总数。这意味着对于相同数量的信息,“字母表方法”可能需要的存储空间是“桶方法”的两倍至六倍。
这种方式在单词较少重复的情况下,会占用更大的空间
The amount of code required by the “bucket method” may run three to five times as much as for the “letter tables method” depending on the application. Also, this latter method could quite probably be written as a subroutine or by a generator in a compiling routine with much greater ease than could the “bucket method.” The final choice of method depends on details of the specific problem and also on operating characteristics of the machine on which it is to be run. It may in some cases be necessary to program and run tests before a final determination can be made. Both methods are an order of magnitude faster than the simple sequential search and we have found them both to be of value in different parts of the FORTRAN for Datatron Project.
根据应用程序的不同,“存储桶方法”所需的代码量可能是“字母表方法”的三至五倍。 同样,与“存储桶方法”相比,后一种方法很可能以子例程或生成器的形式在编译例程中编写。 方法的最终选择取决于特定问题的细节以及运行该方法的机器的运行特性。 在某些情况下,可能需要对程序进行编程和运行,然后才能做出最终确定。 两种方法都比简单的顺序搜索快一个数量级,并且我们发现它们在Datatron项目的FORTRAN的不同部分都具有价值。
作者René de la Briandais 是一个法国人的名字, 这篇文章是最早描述Trie树或者是前缀树的文章, 作者的信息在网上已经找不到了.
从文章里作者提出了一个外部查找的优化方案, 如何能更快的实现文件的查找, 总体上是多路树的结构, 在The Art of Computer Programming (vol. 3_ Sorting and Searching)的多路树的章节也讲到过多路树非常适合大文件的外部查找, 其优势在于相关的多个节点可以做为一个页面,从而减少查找访问次数。
Trie
Trie树的这个名字提出者是Edward Fredkin, 19岁那年离开加州理工学院(Caltech)一年后加入美国空军(USAF)成为战斗机飞行员。他是麻省理工学院的计算机科学教授,是加州理工学院的半导体杰出学者,还是波士顿大学的物理学研究教授。
弗雷德金最初的研究重点是物理学。 然而,他于1956年被空军派往麻省理工学院林肯实验室时,开始涉足计算机领域。 1958年退役后,弗雷德金(Fredkin)被J. C. R. Licklider雇用,在研究公司Bolt Beranek&Newman(BBN)工作。 在1959年12月在波士顿举行的东部联合计算机会议上看到PDP-1计算机原型后,弗雷德金建议BBN购买第一批PDP-1以支持BBN的研究项目。 新硬件没有任何软件。
弗雷德金(Fredkin)编写了一个名为FRAP(无规则汇编程序,有时也称为弗雷德金的汇编程序)的PDP-1汇编程序,以及它的第一个操作系统(OS)。 他组织并成立了一个名为DECUS的用户组,并参与了早期项目。 Fredkin与PDP-1的设计师Ben Gurley合作,对硬件进行了重大修改,以支持通过BBN分时系统进行分时。 他发明并设计了第一个现代中断系统,Digital将其称为“Sequence Break”。他继续成为人工智能(AI)领域的贡献者。
他的主要贡献是 Reversible Computing 和 celluar automata 他本人分享 https://www.youtube.com/watch?v=ROv1HX-gdas 他的一些视频 https://www.youtube.com/channel/UCTHt_lIzcOBV65qi83Nrtng 很传奇的一个人物
from wiki https://en.wikipedia.org/wiki/Edward_Fredkin